下載模型大多是為了 fine-tune 使用,由於模型大小會受限於硬體資源,如果希望產品有更好的回答效果,大多會嘗試使用模型開發商所提供的 API 來串接它們所提供的雲端 LLM 模型。
而如何將 LLM 串接到自己的程式碼當中,接觸過 Gen AI 開發就一定使用過 Langchain,簡單來說可以實體化各個 components,然而 Langchain 強大的地方在於可以透過設計 chain 的方式將不同的 components 串接在一起,接下來三天著重在 chain 的設計上,以及自己在開發過程中踩過的雷。
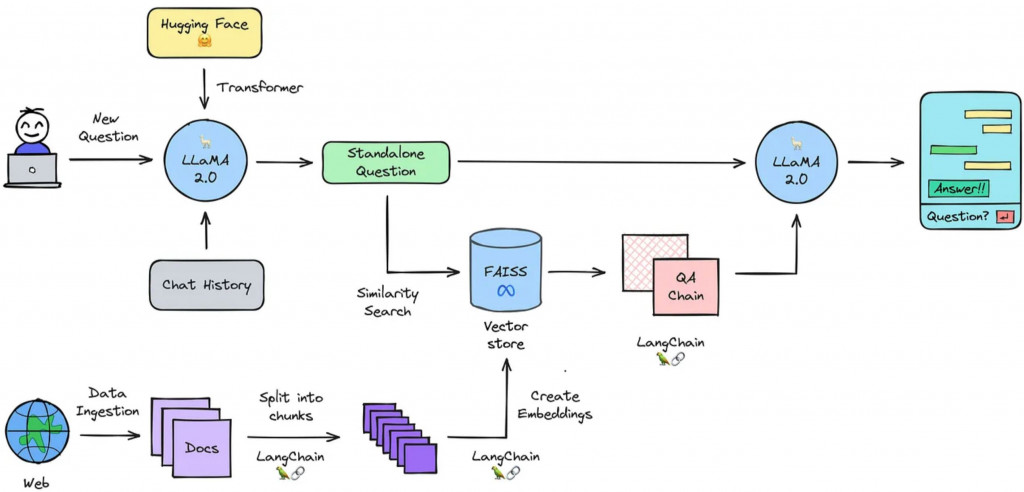
Picture Source
這裡有一個簡單清楚,但功能已經算是很完整的 RAG Process Flow,Langchain 強大的地方就在於已經為中間的所有組件與連結建立好解決方案,而每一個組件又可以從這個清單中簡單的替換成其他解決方案。
讓我們簡單順過架構圖,之後進入到系統設計課程也會更快上手:
要能夠善用上述元件,組合設計出產品架構圖,就必須先了解 Runnable 概念,可以將上述的所有組件和 chain 都是為一個 Runnable (可執行組件) 透過遵守 Runnable Protocol 建立共同的存取方式,而這些 Runnable 則可以透過 Sequences, Parallel, Passthrough 等方式串接成鏈,最後透過 Runnable Interface 的指令將變數輸入進整條 chain 當中,今天先介紹其中 Runnable Interface。
Runnable Interface 是為開發者提供,與模型或 chain 互動的統一介面。
主要有以下三種,又可以分為同步和異步場景。
示範前我們先定義 llm 和 chain:
from langchain_mistralai import ChatMistralAI
from langchain.prompts import ChatPromptTemplate
llm = ChatMistralAI(model="mistral-large-latest")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | llm
chain.invoke({"topic":"SI Dream Engineering"})
await chain.ainvoke({"topic":"SI Dream Engineering"})
'''
output: AIMessage(content='What do you call a sleep-deprived engineer?\n\nA "Si-esta" engineer!', response_metadata={'token_usage': {'prompt_tokens': 11, 'total_tokens': 33, 'completion_tokens': 22}, 'model': 'mistral-large-latest', 'finish_reason': 'stop'}, id='ID', usage_metadata={'input_tokens': 11, 'output_tokens': 22, 'total_tokens': 33})
'''
chain.batch([{"topic":"SI"},{"topic":"Dream"},{"topic":"Engineering"}])
await chain.abatch([{"topic":"SI"},{"topic":"Dream"},{"topic":"Engineering"}])
'''
output:
[AIMessage(content='... joke of SI ...', response_metadata={'token_usage': {'prompt_tokens': 9, 'total_tokens': 89, 'completion_tokens': 80}, 'model': 'mistral-large-latest', 'finish_reason': 'stop'}, id='ID', usage_metadata={'input_tokens': 9, 'output_tokens': 80, 'total_tokens': 89}),
AIMessage(content='... joke of Dream ...', response_metadata={'token_usage': {'prompt_tokens': 9, 'total_tokens': 28, 'completion_tokens': 19}, 'model': 'mistral-large-latest', 'finish_reason': 'stop'}, id='ID', usage_metadata={'input_tokens': 9, 'output_tokens': 19, 'total_tokens': 28}),
AIMessage(content='... joke of Engineering ...', response_metadata={'token_usage': {'prompt_tokens': 9, 'total_tokens': 26, 'completion_tokens': 17}, 'model': 'mistral-large-latest', 'finish_reason': 'stop'}, id='ID', usage_metadata={'input_tokens': 9, 'output_tokens': 17, 'total_tokens': 26})]
'''
for s in chain.stream({"topic":"SI Dream Engineering"}):
print(s.content, end="", flush=True)
async for s in chain.astream({"topic":"SI Dream Engineering"}):
print(s.content, end="", flush=True)
'''
output:
Sure, here's a light-hearted joke for you:
Why don't SI Dream Engineers play cards in the jungle?
Because there are too many cheetahs!
(It's a play on words: "cheetahs" sounds like "cheaters")
'''
ref.


 iThome鐵人賽
iThome鐵人賽